Mit Knowledge Graph ist ein Präsentationssystem des Wissens gemeint, das von der Suchmaschine Google seit Mitte 2012 genutzt wird, um die Suchergebnisseiten mit Informationen anzureichern. Bei einer passenden Suchanfrage werden seither über, zwischen und neben den klassischen Trefferlisten und den Werbeanzeigen Infoboxen eingeblendet, die Wissen präsentieren. Die Suchmaschine antwortet somit nicht mehr nur auf die Frage "Wo finde ich Informationen zum Thema", sondern geht ganz konkret auf den inhaltlichen Kern der Anfrage ein.
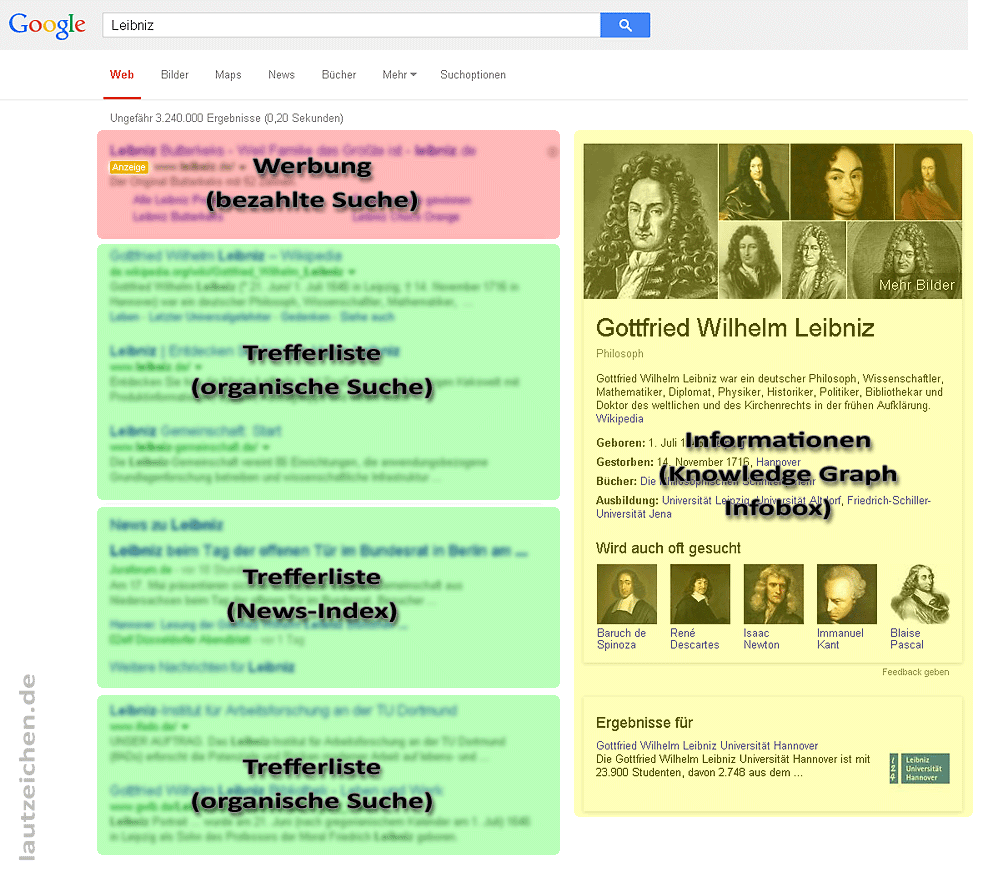
Gesammeltes Wissen, strukturiert aufbereitet
Der Knowledge Graph greift hierfür auf unterschiedliche Datenbestände zurück, beispielsweise auf Informationen der Wikipedia-Enzyklopädie, auf Daten von Firmen-Websites, auf Inhalte von Google Plus oder Google Maps. Bei konkreter Suchanfrage wird dann Allgemeinwissen zu Personen der Zeitgeschichte eingeblendet, werden Daten zu Firmen und aktuelle Beiträge einer Google-Plus-Firmenseite angeboten, Informationen zum Kaloriengehalt von Lebensmitteln oder Öffnungszeiten von Gaststätten präsentiert.
Die Anfragen werden hierbei vermutlich in Echtzeit beantwortet, was ein höchst effizient arbeitendes Datenbanksystem mit strukturiert aufbereitetem Datenbestand voraussetzt. Strukturiert bedeutet hierbei, dass Fakten separiert, gekennzeichnet und klassifiziert sein müssen, um sie als solche abfragen zu können: Während der Informationsgehalt von "Wolfgang Amadeus Mozart, 27.1.1756 - 5.12.1791" für Menschen offenkundig ist, stellt diese Zeichenkette für Computer eine belanglose Aneinanderreihung von Bytes dar. Erst nach Unterteilung und Etikettierung als [Vorname | Nachname | Geburtsdatum | Sterbedatum] werden aus der Zeichenfolge inhaltsbezogene Einheiten.
Diese Aufgabe der Strukturierung wirkt zunächst trivial. Die Komplexität wird aber deutlich, wenn man sich die Menge der Daten vor Augen führt, die die Google-Robots täglich aufs Neue von den unzähligen Internetseiten holen. Aus diesem Datensalat rein maschinell relevante Inhalte zu extrahieren und zu deklarieren, stellt die eigentliche Meisterleistung seitens Google dar. Zum offiziellen Start des Knowledge Graph im Mai 2012 habe der strukturierte Datenbestand "more than 500 million objects, as well as more than 3.5 billion facts about and relationships between these different objects" umfasst (siehe Introducing the Knowledge Graph: things, not strings).
Von der Such- zur Findmaschine
Eine weitere Aufgabe auf dem Weg zum antwortenden Knowledge Graph bestand darin, die eingetippten oder inzwischen auch eingesprochenen Suchphrasen intentional verstehen zu lernen: Liegt ein Kaufinteresse vor? Werden allgemeine Informationen verlangt? Steht die Aktualität im Vordergrund oder geht es um geografische oder zeitliche Orientierung? Und konkret: Ist mit "Mars" der Planet oder eine Gottheit gemeint? Wird mit "Kölsch" nach einer Brauanleitung gesucht oder ein Dolmetscher verlangt. Soll mit "Arsen" die Schwiegermutter vergiftet werden (liegt also ein Kaufinteresse vor), oder wird nach einem außergewöhnlichen Vornamen gesucht?
Auch hier steht die digitale Textverarbeitung vor der Herausforderung, aus einer Zeichenfolge einen 'Sinn' zu extrahieren, den begrifflichen Fragekern zu erkennen. Erst nach Auflösung der Frage "Bin ich etwa von Mars so fett geworden" in inhaltstragende Bestandteile und belanglose Füllwörter kann der Bezug zu den im Knowledge Graph gesammelten Daten hergestellt werden - in diesem Fall zum Speicherbereich: Essen -> Genussmittel -> Schokoriegel -> Mars -> Fettgehalt.
Auf dem Weg zum semantischen Orakel

